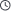



Why AIOps Matters Now
Imagine waking up at 3:00 AM to a barrage of urgent notifications. Your phone is buzzing relentlessly, and your inbox is filling up with hundreds of critical alerts. The digital storefront is slowing down, customers are complaining, and your entire infrastructure seems to be blinking red. You assemble a war room, pulling together database administrators, network engineers, and system administrators. Everyone looks at their isolated dashboards, asserting that their specific layer is functioning normally while the business loses thousands of dollars every minute.
This nightmare scenario is the daily reality of modern IT infrastructure. The sheer complexity of contemporary systems—characterized by distributed microservices, multi-cloud architectures, and massive scales of data—has outpaced human capability. Traditional, static monitoring tools that rely on manual thresholds simply cannot keep up with this dynamic landscape. They create a mountain of noise, leading to severe alert fatigue and making it nearly impossible to identify the actual root cause of an incident before it impacts end-users.
To survive and thrive in this environment, operations teams must shift from reactive firefighting to proactive, intelligent management. This is precisely why specialized AIOps Training has become the single most valuable advancement for modern technology professionals. By blending data science with systems engineering, enterprise teams can transform overwhelming noise into actionable operational intelligence. If you are looking to master these modern methodologies and build future-proof infrastructure skills, AiOpsSchool provides the comprehensive framework needed to bridge the gap between traditional engineering and artificial intelligence.
What Is AIOps?
At its core, What is AIOps can be understood as the application of artificial intelligence, machine learning, and advanced data analytics to automate and improve IT operations. Short for Artificial Intelligence for IT Operations, the term represents a fundamental shift away from manual monitoring and human-dependent troubleshooting. Instead of relying on engineers to write complex rules for every potential failure scenario, artificial intelligence digests vast quantities of operational data to find patterns that a human eye would completely miss.
Think of it as adding a highly intelligent assistant to your operations team. This assistant continuously monitors every layer of your technology stack, remembers historical behavior, notices when things deviate from the norm, and connects the dots across multiple platforms. It bridges the gap between disparate data silos, enabling teams to manage complex systems at unprecedented scale.
Key Operational Concepts You Must Know
Before diving deeper into platforms and tools, it is vital to understand the foundational pillars that govern AIOps in IT operations. Without these core concepts, implementing artificial intelligence in your workflow is ineffective.
Observability and Telemetry
Traditional monitoring tells you when a system is broken, but observability allows you to understand why it is broken by examining its external outputs. This relies entirely on telemetry data, which is categorized into three major types:
- Logs: Chronological records of discrete events that occurred within an application or system, providing high-fidelity text context.
- Metrics: Numerical values measured over intervals of time, such as CPU utilization or memory consumption, providing a high-level view of health.
- Traces: End-to-end journeys of a request as it flows through a distributed system, mapping out exactly how microservices interact.
Event Correlation and Clustering
In a large enterprise environment, a single network switch failure can trigger thousands of downstream alerts from applications, databases, and virtual machines. Event correlation is the process of taking this massive sea of noisy alerts and grouping them into a single, cohesive incident. By recognizing that these alerts are mathematically and chronologically related, the system reduces alert fatigue and points engineers directly to the source of the issue.
Baseline vs. Anomaly
Traditional monitoring uses rigid, hardcoded thresholds—for instance, triggering an alert if CPU usage exceeds 85%. However, a database might naturally hit 90% CPU every Tuesday during a scheduled backup. AIOps establishes a dynamic baseline of what normal looks like based on historical trends. An anomaly is detected only when behavior deviates significantly from this dynamic baseline, drastically minimizing false positives.
Automation and Remediation
The ultimate evolution of intelligent operations is moving from detection to action. Once an incident is identified and correlated, automated remediation workflows can be triggered to resolve the issue without human intervention. This could involve restarting a degraded microservice container or automatically scaling up cloud resources to handle an unexpected traffic spike.
AIOps for Beginners
For engineers looking to accelerate their career progression, focusing on AIOps for beginners is an incredibly strategic move. The technology industry is undergoing a massive shift, and those who position themselves early will reap the greatest professional rewards. Here are three reasons why now is the perfect time to start learning:
- The Scalability Crisis: Modern enterprise infrastructures are growing exponentially. Human teams cannot scale linearly with the amount of data being generated, making algorithmic assistance a strict operational requirement rather than a luxury.
- High Market Demand: Organizations across the globe are aggressively hiring professionals who can combine traditional infrastructure expertise with data-driven automation, leading to highly lucrative career paths.
- The Transition from Reactive to Proactive: Companies are no longer willing to tolerate prolonged downtimes. Learning these skills allows you to deliver the high-availability environments that modern businesses demand.
AIOps vs DevOps vs MLOps
Because these modern operational terms sound similar, professionals frequently confuse their core objectives. To clarify where each discipline sits within the broader technology lifecycle, consider the following structural comparison:
| Concept | Primary Focus | Core Question It Answers |
| AIOps vs DevOps | Applying machine learning and data science to automate, optimize, and streamline IT infrastructure management and real-time incident response. | “How can we leverage algorithmic intelligence to keep our running production environments healthy, resilient, and noise-free?” |
| DevOps | Bridging the gap between software development and IT operations through continuous integration, continuous delivery (CI/CD), and cultural alignment. | “How can we accelerate the software development lifecycle to deliver high-quality code changes to production safely and frequently?” |
| AIOps vs MLOps | Standardizing, deploying, monitoring, and managing the lifecycle of machine learning models in operational production environments. | “How do we build a repeatable framework to train, version, deploy, and monitor our data science models reliably at scale?” |
Platform Implementation vs. Culture — What’s the Real Difference?
A frequent mistake that enterprises make when adopting these technologies is treating them purely as a product purchase. They assume that buying an expensive license and installing a platform will instantly solve their availability and reliability problems. In reality, modern operations require a profound balance between software engineering tools and organizational culture.
Implementing a platform involves configuring agents, feeding telemetry data into algorithms, and setting up dashboards. While these technical steps are necessary, they are completely ineffective without a parallel shift in operational habits. Teams must learn to break down data silos, build trust in automation, and rewrite their internal processes to support cross-team collaboration. If your engineering culture remains highly reactive and isolated, even the most sophisticated platform will simply generate advanced charts that nobody acts upon.
True transformation requires moving away from the tool-only mindset and investing heavily in the human elements of change management. Engineers must be trained through AIOps Training not just on how to use a specific software interface, but on how to fundamentally build the operational habits and trust needed to act on its output. This cultural shift ensures that AIOps in IT operations delivers genuine, transformative value rather than just another dashboard layer.
| Operational Dimension | Platform Implementation (The Tool) | Cultural Transformation (The Practice) |
| Primary Goal | Deploying software agents and connecting ingestion pipelines. | Building trust in data outputs and changing day-to-day team habits. |
| Focus Area | Technology stack integrations and algorithmic configurations. | Overcoming organizational silos and establishing collaborative workflows. |
| Common Pitfall | Assuming software configuration automatically fixes bad processes. | Ignoring technical training, leading to low adoption rates. |
| Long-Term Value | Provides the technical capability to process telemetry at scale. | Empowers teams to actually act on automation and drive business value. |
Core AIOps Use Cases
When examining the practical applications of AIOps use cases, we see clear, measurable impacts across the entire engineering lifecycle. These use cases highlight how AIOps in IT operations shifts the paradigm from manual investigation to software-driven resolution.
- Anomaly Detection: Evaluating live streams of telemetry against historical models to catch hidden anomalies before they trigger widespread system outages.
- Event Correlation: Bundling thousands of redundant, cascading alerts into a single actionable incident record, completely eliminating alert fatigue.
- AIOps Root Cause Analysis: Tracing dependencies across complex, multi-tiered architectures to pinpoint the exact code line, database query, or hardware component causing a failure.
- Predictive Capacity Planning: Analyzing long-term resource utilization trends to accurately project future cloud spend and infrastructure constraints months in advance.
- Automated Remediation: Executing pre-verified software scripts to fix known operational anomalies instantly, completely bypassing manual on-call intervention.
Real-World Use Cases of Modern Operations
To see how these concepts translate into concrete business value, let us look at how different industries leverage these specialized capabilities to solve complex problems:
In the highly competitive e-commerce sector, a massive global retailer utilized advanced AIOps use cases to address transient microservice latency spikes during peak holiday shopping events. By analyzing thousands of distributed traces simultaneously, the platform executed rapid automated root cause detection, identifying a misconfigured database connection pool and automatically scaling resources to prevent cart abandonment. This clear implementation of AIOps in IT operations minimized human troubleshooting time and completely preserved revenue.
In the financial services landscape, a major retail banking institution integrated intelligent monitoring into their core infrastructure to protect against transaction failures and latency anomalies. The system automatically correlated a sudden drop in API throughput with a silent background network configuration change, allowing the operations team to revert the modification within minutes.
Within the enterprise software space, a fast-growing SaaS provider leveraged predictive capacity planning models to avoid multi-tenant resource starvation during high-demand periods. By accurately forecasting storage utilization trends across thousands of independent databases, the platform proactively provisioned cloud storage assets ahead of demand spikes.
AIOps Tools You Should Know
To effectively build an automated environment, engineers must familiarize themselves with the prevailing industry ecosystem. The modern AIOps Tools landscape is diverse, consisting of specialized applications designed to handle distinct parts of the telemetry and automation pipeline. Reviewing a comprehensive AIOps tools list helps engineers choose the right instruments for their specific enterprise architecture.
- Monitoring & Observability Platforms: Comprehensive enterprise platforms such as Datadog, Dynatrace, New Relic, and ScienceLogic specialize in ingesting massive volumes of metrics, logs, and traces, utilizing built-in machine learning engines to highlight architectural anomalies.
- Event Correlation & ITSM Tools: Platforms like BigPanda, Moogsoft, PagerDuty, and ServiceNow focus on taking noisy alert streams from multiple separate inputs, deduplicating them, and structuring them into clean, prioritized incident response tickets.
- Open-Source Stacks: For teams building customized internal platforms, combining Prometheus for metric gathering, Grafana for visualization, and OpenTelemetry for vendor-agnostic data collection provides an incredibly powerful, flexible foundation.
- Cloud-Native Services: Major public hyperscalers offer built-in, proprietary machine learning operations engines, including AWS DevOps Guru, Azure Monitor Baseline Alerts, and Google Cloud Service Intelligence, tailored for native cloud deployments.
Understanding how to stitch these tools together into a unified operational strategy is a critical phase of professional development. Initiating a detailed AIOps Tutorial is the logical next step for any engineer who wants to gain direct, practical experience configuring these advanced enterprise toolchains.
Common Mistakes in Operations Engineering
Transitioning to automated operations is a complex journey filled with hidden obstacles. Organizations frequently stub their toes on the exact same procedural hurdles, which can completely disrupt the rollout of AIOps in IT operations.
- Over-Alerting and Ignoring Noise Reduction: Many teams turn on machine learning discovery models across all data feeds simultaneously without establishing clear filtering guidelines. This leads to an explosion of trivial anomaly notices, worsening alert fatigue. The Fix: Focus algorithmic tracking on high-priority business metrics first, gradually expanding scope.
- Treating the System as “Set and Forget”: Artificial intelligence requires continuous operational context. Infrastructure changes, new code releases, and shifting user behaviors will alter what constitutes a normal baseline. The Fix: Treat machine learning models as living assets that require regular validation.
- Skipping Data Quality and Normalization: An algorithm is only as good as the information it consumes. If your logs are poorly structured and metrics lack consistent tagging, your AIOps root cause analysis will produce inaccurate conclusions. The Fix: Prioritize clean telemetry data hygiene before turning on advanced automation.
- Automating Remediation Too Early Without Trust: Attempting to build fully automated, self-healing systems before verifying the accuracy of your detection logic can lead to disaster. An incorrectly triggered automated script could inadvertently shut down healthy production servers. The Fix: Build operational trust by running automated workflows in advisory mode first, requiring manual sign-off before execution.
- Lack of Cross-Team Buy-In: If infrastructure engineers, application developers, and security professionals operate in isolated silos, they will refuse to trust a centralized operational intelligence platform. The Fix: Cultivate shared organizational buy-in and collaborative operational patterns through structured team alignment.
AIOps for SRE
Site Reliability Engineering (SRE) focuses on treating operational challenges as software engineering problems. For these professionals, integrating AIOps for SRE methodologies is a natural and powerful evolution. SRE teams rely heavily on quantitative measurements to maintain system stability, and intelligent software provides the precise scaling mechanism needed to protect core operational metrics.
Consider the classic SRE lifecycle metrics: Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR). In a traditional setting, finding a silent error requires manually querying raw log files and building ad-hoc dashboards—a process that can take hours. By leveraging machine learning models to automatically group related alerts and pinpoint the exact source of failure, the time required to detect and resolve an issue drops from hours to seconds.
Furthermore, this intelligence directly safeguards an organization’s Service Level Objectives (SLOs) and Error Budgets. By proactively identifying subtle performance degradation trends before they breach defined error thresholds, automated operations protect the user experience and ensure the business remains securely within its operational compliance boundaries.
Seeing AIOps in Action
To truly appreciate the power of modern intelligence within infrastructure management, let us walk through a detailed, step-by-step operational scenario. This reveals how manual troubleshooting models pale in comparison to algorithmic automation.
The Problem
At 2:15 PM on a Friday, an online banking platform experiences a sudden, catastrophic drop in successful checkout transactions. Simultaneously, thousands of independent alerts trigger across the infrastructure: database latency warnings spike, container CPU usage climbs to maximum levels, web servers log 504 gateway timeouts, and third-party authentication requests begin failing. In a traditional environment, separate engineering teams would spend hours debating which alert was the root cause and which ones were merely downstream symptoms.
The Intelligent Resolution Sequence
Instead of relying on human sorting, the organization’s platform handles the crisis through a series of automated steps:
- Ingestion & Deduplication: The centralized platform ingests the massive wave of incoming system alerts, instantly recognizing that they are all chronologically tied to the same business transaction failure.
- Contextual Clustering: Using real-time topology maps, the system groups the thousands of separate notifications into a single, high-priority primary incident ticket.
- Root Cause Identification: The system executes an advanced AIOps root cause analysis, tracing system behavior backward through the infrastructure dependency graph. It completely bypasses the noisy web server alerts, pinpointing the actual root cause: a newly committed database schema update that omitted a critical lookup index.
- Automated Remediation Execution: The platform flags the faulty deployment and automatically triggers an integration script that gracefully rolls back the database migration to the last known stable state.
The Measurable Result
The entire operational incident—from initial performance deviation to complete resolution—takes exactly 42 seconds. This complete application of AIOps in IT operations saves the organization an estimated $120,000 in potential transaction losses, prevents a massive public relations headache, and minimizes engineer burnout.
How to Become an Operations Expert — Career Roadmap
Transitioning your career into this highly sought-after domain requires a structured, intentional approach. Following a clear learning roadmap will optimize your educational journey.
- Master Foundational IT and Monitoring Principles: Develop a deep, practical understanding of core systems engineering, network protocols, cloud architecture, and traditional monitoring configurations.
- Learn Core Algorithmic and Data Concepts: Develop a solid grasp of how machine learning models process operational data. Understand the mechanics behind dynamic baselining, pattern recognition, and anomaly detection formulas.
- Gain Hands-On Tool and Automation Practice: Spend significant time building actual labs with enterprise toolsets. Learn how to configure comprehensive open-source observability infrastructure and construct programmatic automation scripts through structured AIOps Training.
- Pursue Industry-Recognized Validation: Solidify your conceptual knowledge and maximize your professional marketability by enrolling in a dedicated AIOps Course. Earning an official AIOps Certification provides formal proof of your specialized expertise to global enterprises.
Frequently Asked Questions
What prerequisites do I need before taking an AIOps Course?
A foundational understanding of basic IT concepts, cloud infrastructure, and traditional systems monitoring is highly beneficial. Familiarity with basic scripting languages like Python or Bash and an understanding of standard operations frameworks will help you maximize the value of an AIOps Course.
How does an AIOps Certification impact my engineering salary?
Professionals who hold an accredited AIOps Certification typically command substantially higher salaries compared to traditional monitoring administrators. Organizations are eager to pay a premium for engineers who can significantly reduce downtime and eliminate alert fatigue using intelligent, software-driven frameworks.
What is covered in an AIOps Foundation Certification syllabus?
An entry-level AIOps Foundation Certification syllabus focuses heavily on foundational operational concepts. Students learn the core mechanics of telemetry data ingestion, the mathematical principles behind dynamic baselining, the logic of event correlation algorithms, and how to design automated incident response workflows.
Can traditional monitoring tools be upgraded to support machine learning?
While some legacy monitoring utilities are retrofitting basic algorithmic capabilities into their existing software interfaces, true modern operations generally require platforms designed from the ground up to handle high-velocity, high-volume multi-source telemetry data pipelines.
Is coding required to succeed in modern IT operations?
Yes, a basic level of programming proficiency is becoming an industry standard. While you do not need to be a full-stack developer, knowing how to write automation scripts, interact with application programming interfaces (APIs), and manage infrastructure as code is critical for scaling automation.
How do machine learning models avoid learning bad behavior?
During the initialization phase of a deployment, engineers help guide the platform by identifying historical windows of healthy operation. This ensures the underlying machine learning algorithms train on clean data profiles and understand true organizational baselines.
Why Get an AIOps Certification?
In an industry where technology paradigms shift rapidly, professionals must continually find ways to validate their skill sets. Pursuing an official AIOps Certification or an AIOps Foundation Certification is one of the most effective ways to differentiate yourself in a crowded job market.
First, it establishes deep technical credibility. Anyone can list “automation” on a resume, but a formal certification demonstrates that you have completed a structured, rigorous curriculum and mastered the complex mathematical and architectural concepts that power modern intelligent systems. It proves to prospective employers that you are ready to architect enterprise-grade automated operations solutions from day one.
Second, a certification path provides a comprehensive learning structure. Instead of trying to piece together random blog posts and disjointed video snippets, a certified educational curriculum ensures you study every critical operational concept in the sequence. This eliminates hidden knowledge gaps, giving you the deep confidence needed to handle complex production environments when real-world crises occur.
Where to Learn AIOps
If you are ready to take control of your career and move into the future of enterprise technology management, finding a high-quality, structured educational partner is paramount. AiOpsSchool offers premium, comprehensive educational programs specifically designed to turn traditional infrastructure engineers into elite, data-driven automation experts.
Through carefully engineered curricula, students gain deep conceptual understanding and real-world execution strategies across every facet of modern intelligent infrastructure management. The training programs focus on:
- AIOps Training: Immersive, end-to-end educational experiences covering data ingestion frameworks, machine learning models, and complex systems architecture.
- AIOps Course: Targeted, deep-dive learning paths focusing on specific infrastructure environments, advanced observability design, and practical enterprise integrations.
- AIOps Certification: Formally validated validation pathways that test your engineering capabilities and provide globally recognized professional credentials.
- AIOps Tutorial: Step-by-step, practical laboratory exercises that guide you through configuring real production tools and writing live automation workflows.
Final Thoughts
The era of manual IT operations monitoring is drawing to a close. As enterprise technology systems continue to grow in scale, complexity, and distribution, the old methodologies of human threshold configuration and reactive firefighting are becoming completely obsolete. The future belongs to those forward-thinking engineers who can successfully blend deep infrastructure expertise with data science, machine learning, and advanced automation frameworks.
Investing in your professional development through comprehensive AIOps Training is the single best step you can take to future-proof your technical career. By earning a recognized AIOps Certification, you position yourself at the absolute forefront of the technology sector, transforming yourself into an indispensable asset capable of leading complex global organizations through their digital modernization journeys.
The opportunity to pioneer this operational revolution is right in front of you. Take the next definitive step in your engineering evolution, master the complex skill sets required to manage tomorrow’s infrastructure, and discover the comprehensive educational resources waiting for you at AiOpsSchool.com.
Leave a Reply
You must be logged in to post a comment.